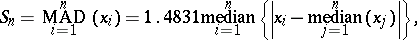En statistique, les M-estimateurs constituent une large classe de statistiques obtenues par la minimisation d'une fonction dépendant des données et des paramètres du modèle. Le processus du calcul d'un M-estimateur est appelé M-estimation. De nombreuses méthodes d'estimation statistiques peuvent être considérées comme des M-estimateurs. Dépendant de la fonction à minimiser lors de la M-estimation, les M-estimateurs peuvent permettre d'obtenir des estimateurs plus robustes que les méthodes plus classiques, comme la méthode des moindres carrés.
Définition
Les M-estimateurs ont été introduits en 1964 par Peter Huber sous la forme d'une généralisation de l'estimation par maximum de vraisemblance à la minimisation d'une fonction ρ sur l'ensemble des données. Ainsi, le (ou les) M-estimateur associé aux données et à la fonction ρ est estimé par
Le M de M-estimateur provient donc du maximum de vraisemblance (maximum likelihood-type en anglais) et les estimateurs par maximum de vraisemblance sont un cas particulier des M-estimateurs.
Types
La résolution du problème de minimisation passe couramment par une différentiation de la fonction cible. En effet, pour chercher , une méthode simple consiste à chercher les valeurs telles que
Dans le cas où cette différentiation est possible, le M-estimateur est dit de type ψ ; sinon, il est dit de type ρ.
Type ρ
Pour un entier positif r, soit et des espaces mesurables, et est un vecteur de paramètres. Un M-estimateur de type ρ est défini par une fonction mesurable . Il envoie la fonction de répartition d'une loi de probabilités sur vers la valeur (si elle existe) qui minimise , soit :
Par exemple, la fonction qui correspond à l'estimateur du maximum de vraisemblance et , avec .
Type ψ
Si est dérivable par rapport à , le calcul de est souvent plus simple. Un M-estimateur de type ψ T est défini pour une fonction mesurable . Il envoie la fonction de répartition d'une loi de probabilités F sur vers la valeur (si elle existe) qui vérifie l'équation vectorielle:
Par exemple, pour l'estimateur du maximum de vraisemblance, on a , avec désignant le vecteur transposé de u et .
Un tel estimateur n'est pas nécessairement un M-estimateur de type ρ, mais si ρ est dérivée et de dérivée continue par rapport à , alors une condition nécessaire pour qu'un M-estimateur de type ψ soit un M-estimateur de type ρ est . De telles définitions peuvent être adaptés aux échantillons finis.
Si la fonction ψ décroit vers zéro quand , l'estimateur est dit décroissant. De tels estimateurs ont d'autres propriétés utiles, comme le rejet des valeurs aberrantes évidentes.
Exemples de M-estimateurs
Parmi les exemples connus de M-estimateurs, on peut citer :
- , ce qui revient à appliquer la méthode des moindres carrés
- (fonction de Huber (en))
- (fonction de Lorentz)
- (bipoids de Tukey)
Articles connexes
- Méthode des moindres carrés
Références
- Peter J. Huber, Robust Statistics, Wiley, 1981, 2004
- Portail des probabilités et de la statistique